
Data Engineering is a Critical Skill
As software engineers grow in their skills, they often begin branching out into new specializations. Maybe backend engineers dabble in the frontend, maybe some embedded engineers play around with some backend code. I'm here to argue that more software developers should at least dabble in data engineering.
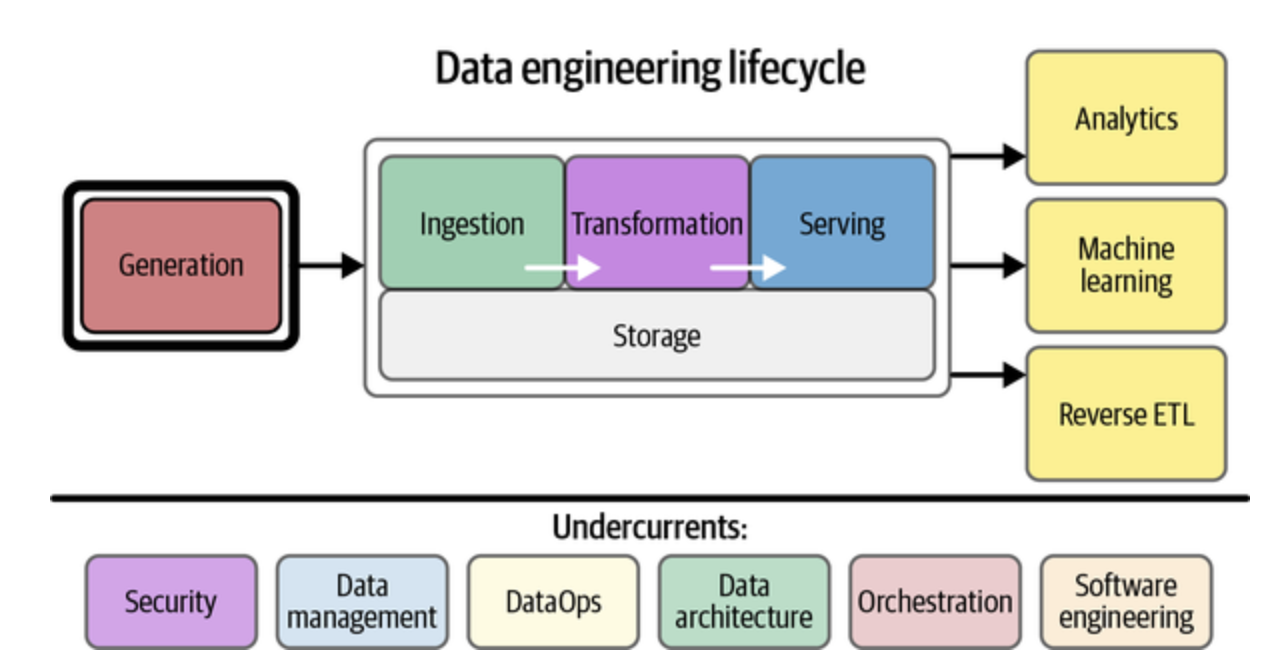
Data engineering is an increasingly important area for software developers to explore, as organizations continue to collect and analyze more data. By gaining a basic understanding of data engineering principles and techniques, software developers can expand their skillset and become more valuable to their organizations. They can also develop a deeper understanding of how data is stored, processed, and analyzed, which can help them design more effective systems and make better decisions. Additionally, as more companies move towards data-driven decision making, software developers with data engineering skills are likely to be in high demand. In short, data engineering is a valuable specialization for any software developer to explore, and can open up new career opportunities and increase their overall value as a professional.
What do Data Engineers do?
Data engineering is the process of building and maintaining the systems that collect, store, and process data. They work with data scientists, machine learning engineers, and analysts of various types to ensure that data is accessible and usable. They work with other software engineers on architecture, information design, and applications. They work with DevOps on complex infrastructure and deployments. They work with management on planning, reporting, and even regulatory compliance. Data engineers can find themselves working with quite a lot of an organization, while simultaneously remaining somewhat invisible.
Ingestion is a major component of data engineering. In short, how does data get "in" to a company's systems. Personally, I've worked on data ingestion for defense, logistics, supply chain, IoT, car rental, marketing, and consumer products. It's a straight forward task, but typically mission critical and required to scale extremely efficiently.
Data processing is the next major component. Once data is into a company's systems, where does it go? What happens to it? Data engineers frequently construct "pipelines" for data to flow through: enriching it for reports, indexing it for search, aggregating it for analytics, pre-processing it for machine learning, and much more. The data processing landscape is diverse, and typically data engineers pragmatically select the tools that let them get the job done with very little custom code. That said, many data engineers are quite comfortable with the distributed systems software engineering required for advanced, large scale data processing. Tools like Apache Spark, Flink, Kafka, Akka and more can help data engineers get these jobs done efficiently.
Once the data is processed, it needs to be stored for use. Data engineers typically develop a deep understanding of what data storage tools are the most useful in a given situation. While the stereotype might have data engineers trying to shoehorn every task into the latest cool tool, the data engineers I know are typically very pragmatic given the constraints of their problems. Relational databases, block storage, object storage, wide column stores, key-value stores, document databases, search engines, message queues, and more can all be target storage systems for data engineers, each with their own sets of use cases. Examples in the wild include systems like PostgreSQL, HDFS, S3, Cassandra, DynamoDB, MongoDB, Elasticsearch, and Kafka.
Finally, data engineers can be responsible for serving data. Analytics, machine learning, and end users can stress even a slightly bad data model or data storage system. Data engineers are well equipped given their data processing and storage knowledge to design query systems that protect the data store and ensure efficient responses and high availability.
Data engineering is a wide skillset, and the role varies from company to company and team to team. The skills listed here are simply the basics when it comes to data engineering.
Why learn data engineering skills?
As the now-old trope goes, "Data is the new oil", and the saying is still true. Wherever you work in a software project, data is inescapable. Maybe you work on the frontend, where your end users will generate click data, or event data. Perhaps your application's backend will generate events, or the database changes will be ingested through CDC. From there, the data you've created will go onwards to data science, machine learning, marketing, finance, and untold other places. By understand the data ecosystem you're interacting with, you can generate better events, create better data, and enable entirely new categories of features for your organization.
More and more products are highly data driven. By understanding the data engineers storage and processing toolkit, you can get a better idea of the work involved to create a highly data driven product and a better understanding of the limits of your systems.
More and more, software engineers need to design more wholistic solutions for their company. The LAMP stack (Linux, Apache, MySQL, PHP) alone is no longer going to cut it if you want to be Facebook. In the world of microservices, data engineers are frequently responsible for critical infrastructure that allows microservices to communicate or replicate data. They are typically responsible for publishing data sets built from the microservice data that can be used to bootstrap new services. Again, their data storage knowledge allows them to help design query, processing, and caching systems required to facilitate complex queries with high performance.
Finally, data engineering can change your career. While "data scientist" and "machine learning engineer" are the hot job titles most people think of, neither can operate without data engineers to build their data substrate. From both personal experience and industry reports, organizations lack the data engineers they need, often halting proposed ML, data science, and analytics projects. Because of all of these factors, data engineering is one of the highest paid specializations in software engineering. Even if you don't make "data engineer" your title, a better understanding of overall system design will certainly help you in the future.
How can I learn more?

Martin Kleppmann masterfully constructs the basics of a data engineers toolkit from the ground up. Though the book focuses more on overall system design fundamentals, these skills all translate directly to being a good data engineer. Highly recommend this book for all software engineers.

This book makes an attempt to package the broad scope of data engineering into a modern, digestible form. Data engineering was a vague concept for quite some time, and this book is helping to crystalize the role.

This book is not data engineering focused, but should be helpful to all software engineers. In a data engineering context, this book can help think through data design and organization rationally to create well designed, highly useful data.

Call this one an "advanced" read. Enterprise data architectures are chaotic and have typically had very little intentional thought applied to them; mostly gluing legacy systems together and copying data around wildly. Zhamak Dehghani introduced the concept of a "Data Mesh", a cohesive design pattern for organizational data systems. If you're a startup already comfortable with microservices and domain driven design, please do yourself a favor and read this book to help your teams start off on the right foot.
Personal Coaching -- If you'd like a personalized plan to grow your data engineering skills, schedule some time with me!